Multi-tenancy is a frequent requirement when architecting distributed systems. A question one ought to ask is how will the system restrict a tenant’s use of resources. After all, without restrictions and given a finite amount of resources, letting a tenant run wild on the APIs will certainly degrade the performance of other active tenants. The answer will take different forms depending on which part of the technology stack is discussed. Such a question was posed to me for the data access layer, in particular, how to limit the JDBC database connections a tenant may acquire.
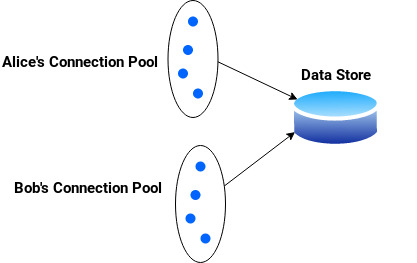
One solution, naively, is to create a connection pool per tenant. However, if we assume that the total number of tenants is 1000 and each tenant requires at most a single database connection, this would equal to 1000 database connections. This is hardly scalable considering the fact that not all tenants will be active at the same time. Of course, the connection pool library can be configured to release idle connections back to the database, but in relative terms, acquiring a database connection is an expensive process which should be minimised (apart from the time it takes to obtain a connection from the database, databases like PostgreSQL bind caches to the connection so closing the connection would lead to cache loss).
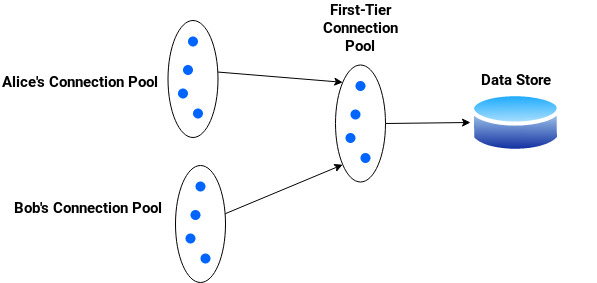
I propose a slightly different solution. Create a connection pool for each tenant, but instead of having the connection pool library draw its connections from the database, have it draw its connections from yet another connection pool. In other words, a first-tier connection pool serving connections to many second-tier connection pools. The benefit we gain from this approach is that second-level connections are released and acquired at a fraction of the time it would have taken to do the same thing directly from the database. This means that a tenant connection can remain idle for a short amount of time before it’s returned to the first-tier pool to be reused by other active tenants with little cost.