This is a trap I’ve observed numerous professionals in the software industry fall into. After all, quite a few people I talk to like to think of messaging as the golden hammer. The sales folks surely want us to believe that this is the case. So many organisations have dug themselves into a hole by using Messaging for ETL that I’m classifying this problem as an anti-pattern and giving it a brief overview.
Context
The business mandates end-of-day reports. The data required for these reports is locked up in CSV files hosted on a FTP server. Each file can range from hundreds to thousands of MBs (i.e., GBs) of records. Records need to be cleansed, massaged, enriched, and transformed from one format to another. Furthermore, some record sets need to be joined with others. At the final stages of the process, the target records have to be written to files and uploaded to a CRM.
Problem
The business decides to use Messaging for ETL. The rationality behind such a decision can vary. One argument might be that some messaging solutions are suited for ETL tasks because they come with a broad set of protocol adaptors and have sophisticated transformation capabilities. The messaging solution could be an ESB, even though the term appears to have fallen out of fashion with the marketing crowd nowadays.
Predictably, the development team models each record as a message. Messaging patterns are used to solve common recurring problems. For example, message queues in order to process the records concurrently between competing consumers; message translators for cleansing, massaging, enriching and transforming the data; aggregator to join records. Applying these patterns is sufficiently easy if the messaging solution has them baked-in.
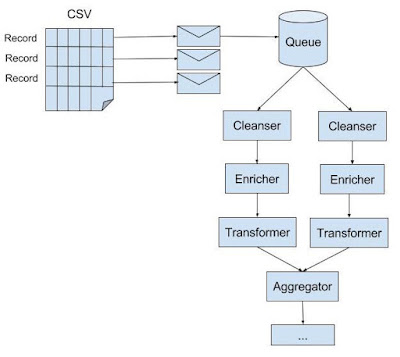
Conceptual dissonance is one aspect to the problem of Messaging for ETL. Another aspect is performance. Treating each record as a packet of data and processing them in a single go leads to a high rate of message traffic that is uniform over time. From my experience, this often causes a significant, if not drastic, drop in throughput simply because most messaging solutions can’t reliably cope with this pattern of traffic. Lock contention is a key factor for this. To illustrate the point, consider the message ID. Several messaging solutions generate a UUID, representing the message ID, and add it to the message before going on to publishing it. Generating a UUID involves obtaining a global lock. As the reader produces hundreds of thousands of messages while it’s churning through the CSV files, concurrently, the aggregator is combining individual messages to produce messages with new UUIDs. Given the stream of messages is constant and without any respite, the result is a high rate of lock contention caused by the reader and aggregator fighting each other out for the lock to generate UUIDs.
Refactored solution
One way to untangle this anti-pattern is to migrate the data intensive logic to another tool. A staging database may be a good initial candidate where you can leverage SQL for the heavy-lifting. Other candidates include ones specifically built for ETL. This doesn’t mean you’re stuck with having to purchase a proprietary ETL tool. Open-source alternatives do exist like Pentaho. If the data you’re transforming is in the realm of “Big Data”, where you need to distribute its processing across a cluster of nodes, map/reduce frameworks such as Apache Spark or Apache Hadoop should be considered.