
We’re inching ever closer to releasing Smooks 2 milestone 3. Featuring in this release will be the powerful ability to declare pipelines. A pipeline is a flexible, yet simple, Smooks construct that isolates the processing of a targeted event from its main processing as well as from the processing of other pipelines. In practice, this means being able to compose any series of transformations on an event outside the main execution context before directing the pipeline output to the execution result stream or to other destinations.
Under the hood, a pipeline is just another instance of Smooks. This is self-evident from the Smooks config element declaring a pipeline:
core:smooks fires a nested Smooks execution whenever an event in the stream matches the filterSourceOn selector. The optional core:action element tells the nested Smooks instance what to do with the pipeline’s output. Out-of-the-box actions include support for merging the output with the result stream, directing the output to a different stream, or binding the output to the execution context’s bean store.
core:config expects a standard smooks-resource-list defining the pipeline’s behaviour. It’s worth highlighting that the nested smooks-resource-list element behaves identically to the outer one, and therefore, it accepts resources like visitors, readers, and even pipelines (a pipeline within a pipeline!). Moreover, a pipeline is transparent to its nested resources: a resource’s behaviour remains the same whether it’s declared inside a pipeline or outside it.
Let’s illustrate the power of pipelines in a real-world use case. Consider this classic data integration problem:
An organisation is required at the end of day to churn through GBs of customer orders captured in a CSV file. Each individual order is to be communicated to the inventory system in JSON and uploaded as XML to a CRM service. Furthermore, an EDIFACT document aggregating the orders needs to be exchanged with the supplier.
A scalable solution powered by Smooks pipelines can be conceptualised to:
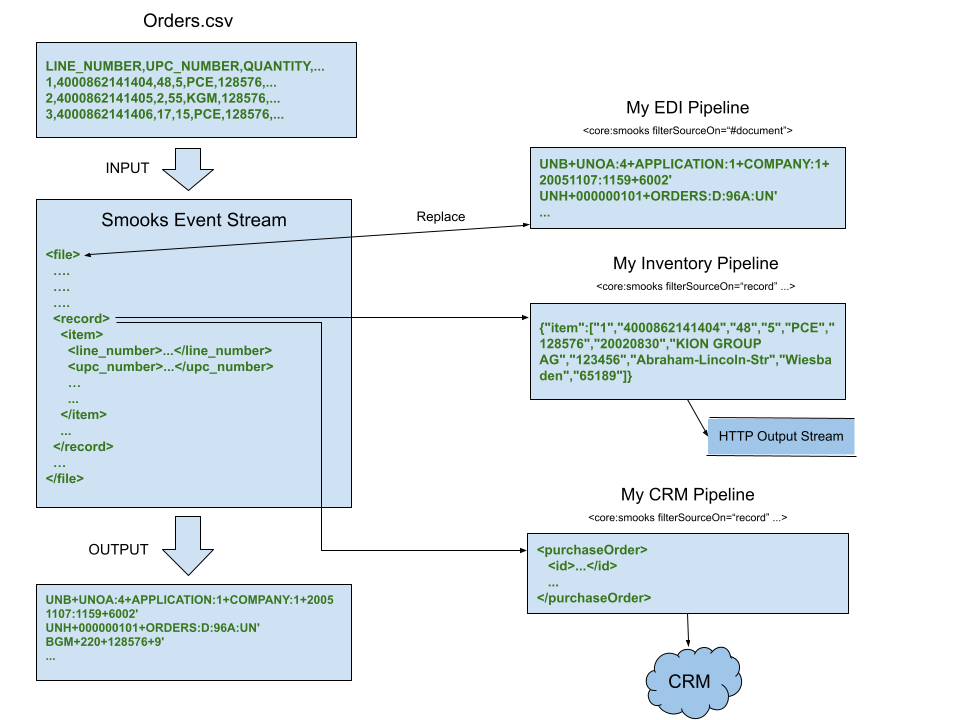
Every data integration point is implemented in its own pipeline. Smooks converts the CSV input into a stream of events, triggering the pipelines at different points in the stream. The document root event (i.e., #document or file) triggers the EDI pipeline while record (i.e., order) events drive the inventory and CRM pipelines. Time to get cracking and implement the solution in a Smooks config.
Reader
The first step to implementing the solution is to turn the CSV file stream into an event stream using the DFDL parser added in Smooks 2.0.0-M1 (alternatively, a simpler but less flexible reader from the CSV cartridge can be used for this purpose):
csv.dfdl.xsd holds the DFDL schema for translating the CSV into XML:
For the above schema, the dfdl:parser turns a CSV stream such as the following:
into the SAX event stream:
The events of interest are the file, record, and item events. Coming up next are the pipeline configurations.
Inventory Pipeline
The inventory pipeline maps each order to JSON and writes it to an HTTP stream where the organisation’s inventory system is reading on the other end:
The filterSourceOn XPath expression selects the event/s for core:smooks to visit. In this snippet, the pipeline visits record events, including their child item events. The root event in the pipeline’s context is record; not file. Although the parent of the item event is record, the latter has no parent node given that it’s the root event in the inventory pipeline. It follows then that the #document selector in the inventory pipeline is equivalent to the record selector.
maxNodeDepth is set to 0 (i.e., infinite) so as to append the item events/nodes to the record tree instead of discarding them. By default, Smooks never accumulates child events in order to keep a low-memory footprint but in this instance we assume the number of item events within a record node is manageable within main memory.
InventoryVisitor visits record events and writes its output to a stream declared within the core:action element (the output stream is registered programmatically). Drilling down to the InventoryVisitor class will yield the Java code:
The AfterVisitor implementation leverages the popular Jackson library to serialise the record element into JSON which is then transparently written out to inventoryOutputStream with Stream.out(executionContext).write(...).
CRM Pipeline
Like the inventory pipeline, the CRM pipeline visits each record event:
Spot the differences between the inventory and CRM pipelines. This pipeline omits core:action because the CrmVisitor resource HTTP POSTs the result directly to the CRM service. Another notable difference is the appearance of a new Smooks 2 reader.
core:delegate-reader delegates the pipeline event stream to an enclosed ftl:freemarker visitor which instantiates the underneath template with the selected record event as a parameter:
core:delegate-reader goes on to feed Freemarker’s instantiated template to CrmVisitor, in other words, core:delegate-reader converts the pipeline event stream into one CrmVisitor can visit:
CrmVisitor’s code should be self-explanatory. Observe org.asynchttpclient.AsyncHttpClient is referenced in visitAfter(...)to perform a non-blocking HTTP POST. All framework execution in Smooks happens in a single thread so blocking calls in the application should be avoided to keep the throughput rate acceptable.
EDI Pipeline
The EDI pipeline requires more thought than the earlier pipelines because (a) it needs to aggregate the orders, (b) wrap a header and footer around the aggregated orders, and (c) convert the event stream into one that the edifact:unparser visitor can digest. After which it needs to write edifact:unparser’s EDI output to the result stream, overwriting the XML stream produced from the dfdl:parser reader. The latter is accomplished with the replace pipeline action:
The selector for this pipeline is set to #document; not record. #document, which denotes the opening root tag, leads to the pipeline firing only once, necessary for creating a single EDIFACT document header and footer. We’ll worry later about how to enumerate the record events.
The subsequent pipeline config leverages core:delegate-reader, introduced in the previous pipeline, to convert the event stream into a stream edifact:unparser (covered furthered on) can understand:
core:delegate-reader delivers the pipeline event stream to its child visitors. Triggered FreeMarker visitors proceed to materialise their templates and have their output fed to the edifact:unparser for serialisation. The previous snippet has a lot to unpack therefore a brief explanation of each enclosed visitor’s role is in order.
-
Header Visitor
On encountering the opening root tag, this FreeMarker visitor feeds the XML header from the header.xml.ftl template to the edifact:unparser. The content of header.xml.ftl, shown next, is static for illustration purposes. In the real world, one would want to generate dynamically data elements like sequence numbers.
-
Body Visitor
The pipeline within a pipeline collects the item events and appends them to the record tree (maxNodeDepth="0") before pushing the record tree down to the enclosed FreeMarker visitor. As a side note, the body logic could be simplified by unnesting the FreeMarker visitor and setting the maxNodeDepth attribute to 0 in the #document pipeline. Unfortunately, such a simplification would come at the cost of reading the entire event stream into memory.
The body.xml.ftl template warrants a closer look:
FreeMarker materialises and feeds the above segment group to the edifact:unparser for each visited record event.
-
Footer Visitor
This FreeMarker visitor is fired on the closing root tag, following the serialisation of the header and body. The footer residing in footer.xml.ftl is also fed to the edifact:unparser:
The final piece to the solution is to configure the edifact:unparser:
As per the unparseOnElement wildcard selector, the pipeline delivers all events generated from the core:delegate-reader visitors to edifact:unparser to be serialised into EDIFACT before the pipeline merges the serialised events with the result stream.
Let’s take a step back to view the complete Smooks config:
A functional version of the solution is available on GitHub. Take it for a spin. Your feedback on Smook’s user forum is most welcome.
* “Pembroke Reverse Osmosis Plant pipeline” by Rrrodrigo is licensed under CC BY-NC 2.0