Event Sourcing is a pattern intended for "capturing all changes to an application state as a sequence of events". As explained by Fowler, the pattern is useful when you want the ability to completely rebuild the application state, perform temporal querying, or replay events. The LMAX platform is a famous example where Event Sourcing is applied to keep all application state in-memory and consequently contributing to the system's surprisingly high throughput and low latency.
While investigating the architectural components of Samza, I came across a component that can be of great help when implementing Event Sourcing: Apache Kafka. Created by the folks at LinkedIn as a solution to their log processing requirements, Kafka is a broker with message replay built-in.
Kafka consumers receive messages from publish/subscribe channels known as topics. A topic is divided into user-defined partitions where a partition can serve messages only to a single consumer process. Balancing the message load between consumers is a matter of adding more partitions to the topic, assigning those partitions to other consumer instances, and finally, publishing messages to all topic partitions in a round robin fashion.
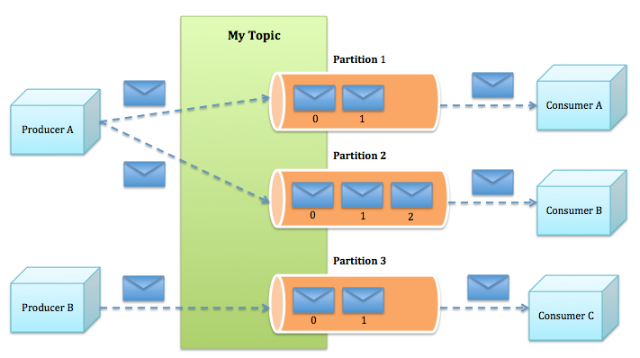
What fascinates about Kafka is that at any point in time a consumer can rewind back through the history of messages and re-consume messages at a particular offset. In the above diagram, Consumer B can consume the latest messages or replay messages, say, starting from offset 1.
At face value we could be forgiven to think that a broker with in-built message replay would have trouble achieving high throughput for large message volumes. After all, Kafka is retaining unconsumed as well as consumed messages on disk: presumably costlier than simply keeping unconsumed messages in memory. However, a few clever design decisions, such as relying on the OS page cache and minimising random disk I/O, gave LinkedIn engineers impressive throughput results when comparing Kafka against both ActiveMQ and RabbitMQ.
With the basic concepts and performance considerations out of the way, let me illustrate my point about Kafka's suitability for Event Sourcing by giving a code example:
The above producer publishes, for a number of times, a message to the topic ossandme on partition 0. In particular, it creates a message by instantiating the KeyedMessage class with the following parameters (line 19):
- Name of the topic to which the message is published.
- ID of the partition the message will sit on.
- Message content, in this case, the time the message was published.
The following consumer pulls messages from the topic ossandme:
For each message received, the application outputs the message's offset on partition 0 in addition to its content (line 50). The first thing to observe is that I've programmed against Kafka's low-level SimpleConsumer API. Alternatively, I could have opted for the High Level Consumer API to reduce development time. I chose the former because with the latter I was unable to find a way to replay any set of messages I wanted.
Event Sourcing comes into play when an exception occurs. On exception, the application rewinds back to the first message in the partition and re-attempts to process all of the partition's messages (line 24). I like the fact that, to get this type of behaviour, I didn't have to introduce a database but simply leveraged the broker's message replay capability. Without a database, I've one less moving part to think about in my architecture.
Kafka is a young project and I'm interested to see how it matures. I'm keen to hear people's experiences using Kafka and whether it proved to be the right solution for them. As the project matures, I suspect we'll hear more often about Kafka in our technical discussions along with the other, more established, open source brokers.